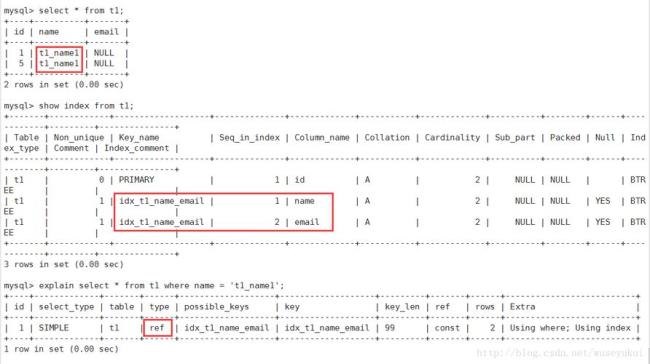
我们先创建一个测试数据库:
快速创建一些数据:
连续执行同样的 SQL 数次,就可以快速构造千万级别的数据:
查看一下总的行数:
我们来释放一个大的 update:
然后另起一个 session,观察 performance_schema 中的信息:
可以看到,performance_schema 会列出当前 SQL 从引擎获取的行数。等 SQL 结束后,我们看一下 update 从引擎总共获取了多少行:
可以看到该 update 从引擎总共获取的行数是表大小的两倍,那我们可以估算:update 的进度 = (rows_examined) / (2 * 表行数)