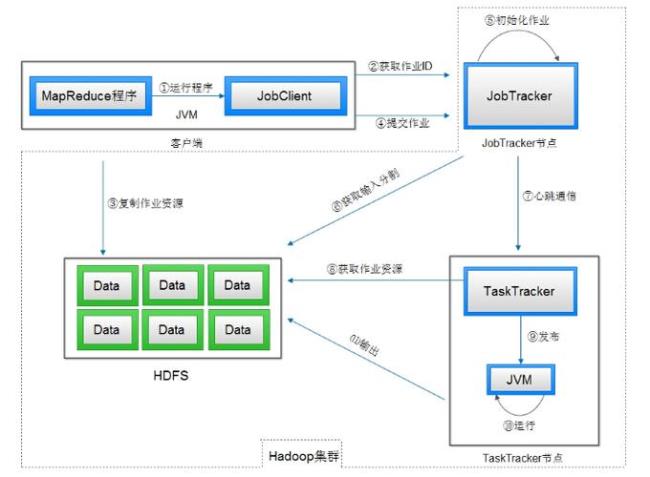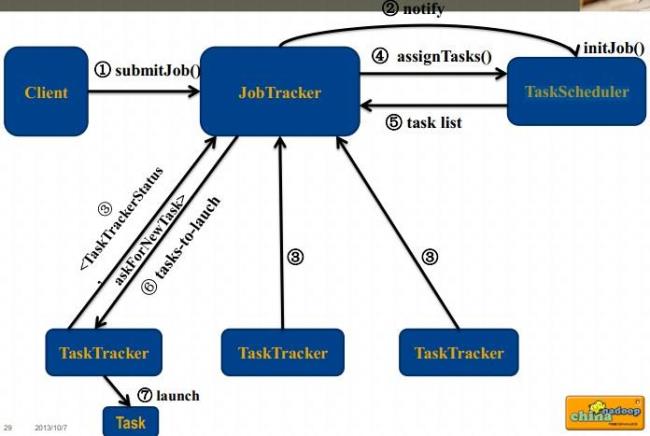
mapreduce主要由以下四个阶段组成:
1、split阶段:
此阶段,每个输入文件被分片输入到map。如一个文件有200M,默认会被分成2片,因为每片的默认最大值和每块的默认值128M相同。
如果输入为大量的小文件,则会造成过多的map数,导致效率下降,可采用压缩输入格式CombineFileInputFormat。
2、map阶段:
此阶段,执行map任务。map数由分片决定,若要增加map数,可增大mapred.map.tasks,若减少map数,可增大mapred.min.split.size。
3、shuffle阶段:
此阶段,将map的输出经过“整理”后给到reduce,也称为“混洗”。分为map端操作和reduce端操作。
在map端,map的输出先写入缓存,当每次缓存快满时,由缓存“溢写”至磁盘,每次溢写都先进行“分区”,并对每个分区的数据进行“排序”和“合并”(可选)。一般会产生多个溢写的文件,这些文件会在map端先被“归并”为一个大的磁盘文件,通知reduce任务来领取自己的分区。
在reduce端,每个reduce任务会从多个map任务领取文件,然后将这些文件进行“归并”,交给reduce任务。
合并(combine)和归并(merge)的区别:对于两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,即复用reduce的逻辑(也可以自己实现combiner类)如果归并,会得到<“a”,<1,1>>。combine为可选,可通过调用 job.setCombinerClass(MyReduce.class)设置这一操作。
4、reduce阶段:
执行reduce任务。reduce数量由分区数决定,结果文件的数量也由此决定,且记录默认按key升序排列。reduce数量可通过mapred.reduce.tasks设置,或在代码中调用job.setNumReduceTasks(int n)方法。